

Behind the Mic with Vasily Rodochenko, Software Engineer at Flix on Scaling Conversational AI with Trust, Testing, and Feedback

Vasily is an ML enthusiast and researcher with 10+ years of experience spanning fintech, compliance, and logistics, backed by a strong foundation in software engineering.
At Flix, he’s channeled his curiosity into AI chatbots, quietly hoping his efforts have made them a bit more user-friendly, understandable, and trustworthy.
We connected with Vasily Rodochenko to explore how agentic AI, continuous feedback, and human insights come together to create trustworthy and impactful customer experiences.
Q1. What motivated you to pursue a career in machine learning and software engineering, and what key steps shaped your path across fintech, compliance, and logistics?
It’s funny to see how big career decisions often start with something simple and personal! When I was at university, the environment was extremely competitive, and coding was actively frowned upon in the maths department – calculus was the only True King we were allowed to serve! But all the cool kids were doing computer science, and as a student you really, really want to be a cool kid! 😉 That’s how my story with machine learning started – it was more about the environment and a bit of a zeitgeist.
Honestly, I didn’t care much about any specific domain back when I started — I just had a toolset. People knew I could do hands-on work, so they’d invite me to approach their problems from a different angle. I’d jump in and try to learn on the fly, however naïve it may sound, filling whatever gaps I could along the way.
In pure academia, it was about coding and sysops. In fintech, it was about knowing how to compare models and understand trade-offs. Sometimes it was about helping people with different backgrounds work together and understand one another. Other times – like with compliance – it was about one brave team vacuum-cleaning the market and saying, “Hey, we don’t know exactly why yet, but some people working for us really want you in. Are you joining?..” Never regretted a single day.
Logistics is somewhat special, though. Working on problems with global, real-world impact and personally experiencing (and even suffering from) the products you help deliver – can be incredibly satisfying. If that’s what you value, it is a fantastic industry to be in.
Q2. How have you leveraged AI, machine learning, and conversational technologies at Flix to enhance customer experience through chatbots and agentic systems?
We have an agentic LLM-based chatbot to handle initial user inquiries. It operates globally and handles thousands of inquiries every day. It was designed to reduce waiting time during spikes, avoid having to navigate through IVRs, and deliver relevant up-to-date information about Flix transportation policies – faster than looking through the website. It can also redirect conversations to real human agents – keeping humans in the loop to handle cases that go beyond simply answering questions or pointing to the right self-serve tool. This was exactly what our talk was about at the Conversational AI & Customer Experience Summit Europe 2025, and… it seems to work and actually helps at times!
Q3. What are some of the most significant challenges you've faced while shifting from an NLU-based bot to an agentic AI model, and how did you overcome them?
LLMs can do things you didn’t explicitly program them to do.
This may look like a single challenge, but there are so many aspects to it! I recently came across the word “blurse” – that’s a perfect description for this trait. First you’re proud that it was able to guide a person to the right webpage even though they formulated their thoughts using a mix of languages – and then it suddenly hallucinates a link.
The industry doesn’t quite have a perfect answer for some of those problems, but we are surely getting slightly better over time! RAG, training, observing, reading, testing, visualizing data – all of it, and something more. Bit by bit you have to make your systems more reliable while maintaining this amazing flexibility.
Q4. What role does user feedback play in the evolution of your chatbot systems, and how do you gather and incorporate it effectively throughout development?
This feedback shapes it all! Literally alpha and omega. The whole chatbot initiative started as an almost vanilla classification problem. We began by collecting most frequently asked questions, but it never stopped there: there’s a constant feedback loop.
We can identify topics for each conversation, we have CSAT in place, and we can more or less gauge overall sentiment. But most importantly, we simply read transcripts every day and multiple people across the org do so for different purposes. We write things down, sit together, and decide what to address next. As simple as that 🙂
Q5. What strategies have you found most effective in designing AI-powered interactions that are both technically robust and emotionally supportive for users?
The most boring ones:
- Use your own product internally
- Read your transcripts and try making them better over time
Human review is unmatched when it comes to spotting subtle issues and finding initial clues. It also just hits differently when it’s personal – your problem, your ride, your luggage. But human reviewers can’t handle large volumes of transcripts, because we’re not wired for that kind of repetitive work, and this is where machine reviews (embeddings, clustering, sentiment scoring) come to the rescue. So just try your best to mix them. Make initial observations and then see what the real magnitude of the problem is by asking machines to search for similar patterns in your datasets.
In our case, it was also a great idea to involve customer support agents. They can moderate LLM responses and provide valuable feedback – especially on market-specific nuances that would otherwise be extremely difficult to identify.
Q6. Can you describe a specific instance where data insights or ML experimentation revealed a major customer pain point and helped drive a key improvement in your AI agent?
Absolutely! When we released our first bot, it was genuinely hard to tell whether we should keep it or kill it. You read the first conversation – it’s great. You read the second – it’s mediocre. Another one – bad. Then good again. So how does it perform overall?
Sentiment? Okay, people are friendly (or not). But is that because the bot is good, or because the customer is simply being polite to a machine? It wasn’t clear at all – until we built our first tool to go through transcripts and answer three very basic questions: “What was it about?”, “Was the problem solved?”, and “Overall, how was it from 0 to 10?”
First, we tried to answer those questions ourselves. Then our LLMs tried. Then we aggregated the data and identified scenarios where the bot was seriously underperforming. We rolled things back, kept polishing it for another two months, and reintroduced it, this time observing a completely different picture in the metrics.
Q7. Could you share a success story where the transition to agentic AI significantly improved customer satisfaction, trust, or conversation outcomes?
For example, this dialogue could barely be possible with an NLU chatbot:
In this scenario, the bot started thinking out of the box and found a way to help—something much closer to the kind of support you’d expect from a human. This is almost impossible to achieve with traditional NLU bots.
We saw an increase in the problem-resolution rate—and, more interestingly, this improvement didn’t come from diverting cases away from human agents. Instead, it came from those “unclassified” conversations, where the intent and even the outcome weren’t clear at all with NLU bots.
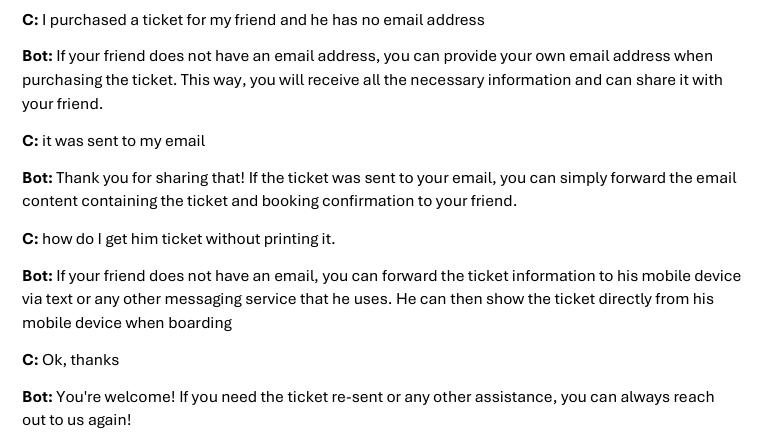
Q8. How do you collaborate with cross-functional teams such as product, design, data science, and customer support to ensure your AI solutions deliver seamless user experiences?
This one is simple: we meet regularly and bring problems to the table! We have a culture of joint sprint reviews where all involved teams present and discuss latest achievements – that gives a high-level overview of “who does what”. But then horizontal interaction comes into play: “Hey, I’ve heard you’re doing X, here’s the problem I spotted” – something like that. May sound trivial, but it works just fine 🙂
Q9. How do you balance innovation in AI with the need to keep chatbot interactions understandable, trustworthy, and user-friendly?
Well. Testing is, while boring, crucial. We have examples of good conversations, failed conversations, hallucinations – everything. Before rolling out a feature or a model, we try to look at it from the perspective of, ” If it had been there at the time, how would it have answered this question?” In a way, it’s quite similar to strategy backtesting in quantitative finance. It’s a bit trickier when LLMs may give different responses in similar setups – but we’re not limited to just one simulation either!
Q10. What best practices have you implemented to ensure transparency, reliability, and consistency in AI-driven customer touchpoints?
Having routines turned out to be surprisingly effective. There’s constant monitoring in place: human review, automated checks, conversation replay, and a feedback loop from both external and internal users (did I mention “use your own tool” already?..).
Q11. How do you stay updated with the latest developments in agentic AI, conversational AI, and machine learning research?
It evolves fast enough for this activity to feel like a full-time job – and even then, it’s probably barely possible to keep up. Anything goes: podcasts, YouTube, pet projects – even small talks. Conferences like CACES are a unique opportunity to meet people who have already tried solving similar problems – and openly share what worked (or, even more importantly, what didn’t) for them. That kind of open exchange is exactly what moves the field forward, so if you’re considering coming, you’re probably on the right track!
Conclusion
Vasily’s perspective offers a grounded and refreshingly honest view into the realities of building agentic AI at scale. Rather than positioning AI as a silver bullet, he highlights the importance of disciplined experimentation, continuous feedback loops, and rigorous human oversight in shaping reliable and meaningful conversational experiences. His journey underscores a powerful truth: the most effective AI systems emerge not from rigid control, but from thoughtful iteration—where human intuition and machine intelligence complement each other.
For organizations aiming to deliver real value through AI, his insights serve as a practical blueprint—one rooted in empathy, resilience, and continuous learning.
“If you found these insights valuable, explore our previous blogs for more conversations, case studies, and expert perspectives on conversational AI and customer experience.”
Join us at Altrusia Global Events as we embark on a transformative journey
Newsletter
[fluentform id="2"]
Copyright © 2026 Altrusia Global Events Pvt Ltd